Live Webinar: Navigating the Challenges to AI Success
Register Now
Optimize LLMs
AI Data
Foundation Models
Platform
Resources
Resources
Blog
Press Releases
Case Studies
White Papers
Events
Webinars
eBooks
Data Sheets
Pre-Labeled Data Sets
Accelerate your AI projects with licensable datasets
Featured Blog
Appen Named a Leader in Everest Group’s PEAK Matrix® Assessment 2024
Read more
Locale
China
Japan
Korea
UK
Client Login
Contact Us
Client Login
Contact Us
Contact Us
Blog
Search
Clear
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Tag
Showing
0
of
100
Date
May 9, 2024
Large Language Model (LLM) Red Teaming: Crowdsourcing the Path to Safer AI
Learn how Appen can help the AI community address this challenge with human-in-the-loop approaches, ensuring LLM development and deployment adhere to the highest standards.
2024-05-09
Read more
May 1, 2024
Appen + Databricks: Using RAG to Build a Better Credit Card Chatbot
Discover how Appen's AI Data Platform (ADAP) and Databricks can be integrated to optimize a credit card customer support chatbot.
2024-05-01
Read more
April 18, 2024
Unleashing the Power of Generative AI: The Vital Role of Subject Matter Experts
Learn how large enterprises can use centralized platforms to unlock GenAI's full potential while maintaining oversight and domain expertise.
2024-04-18
Read more
April 16, 2024
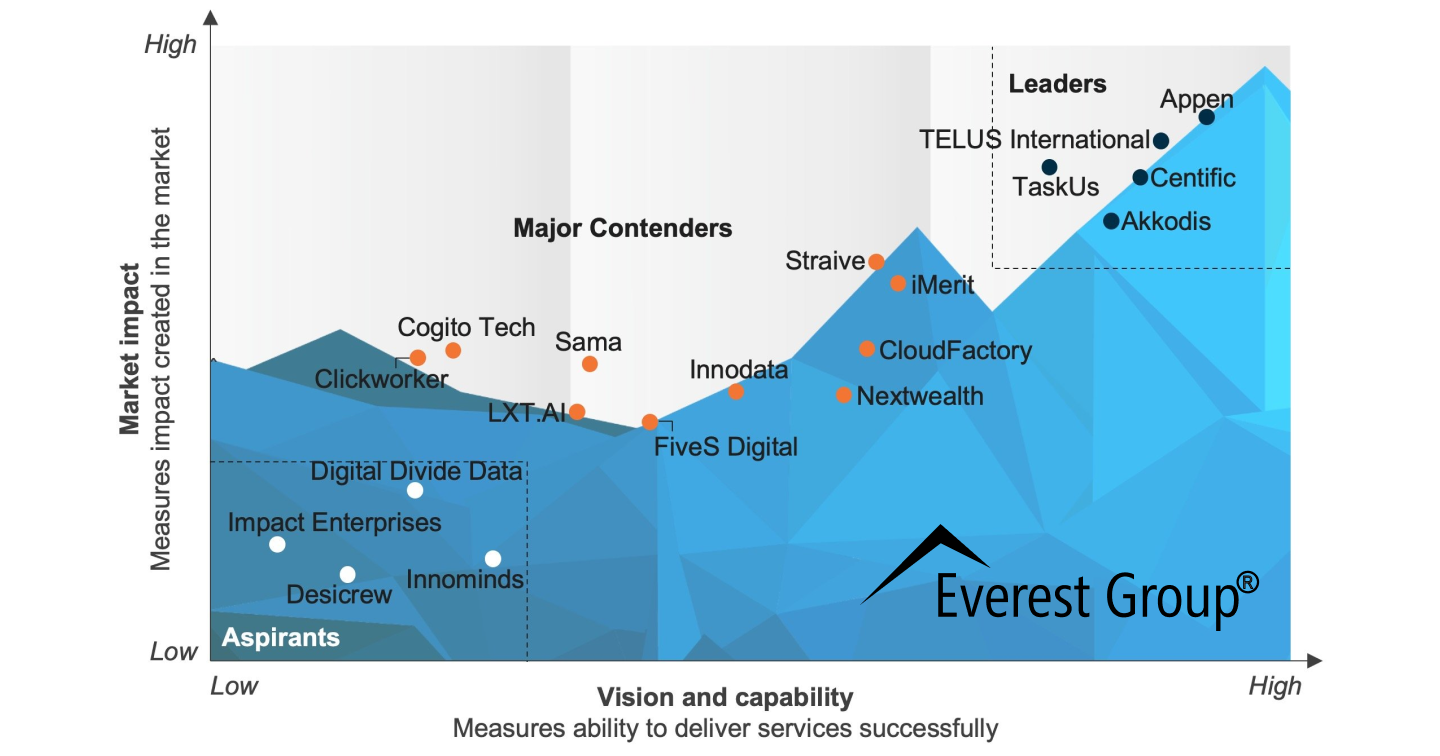
Appen Named a Leader in Everest Group’s PEAK Matrix® Assessment 2024
Appen has been recognized as a Leader in Everest Group’s Data Annotation and Labeling (DAL) Solutions for AI/ML PEAK Matrix® 2024. The report, from this established global research firm, evaluated 19 providers on market impact, vision, and capability
2024-04-16
Read more
April 11, 2024
Understanding LLM Context Windows: Implications and Considerations for AI Applications
Learn what context windows are, how they affect AI, and what organizations should consider when using LLMs.
2024-04-11
Read more
April 10, 2024
Boosting Data Quality with Appen's Human-centric AI Detector Model
Explore how Appen has achieved many milestones and developed innovative methods to enhance the quality of human-generated data for AI model training.
2024-04-10
Read more
Load more